- 1. 大数据生态圈
- 大数据生态圈
- 1.1. 大数据常用技术简介
- Flume-日志收集工具
- sqoop-数据同步传输工具
- Zookeeper-分布式协作服务
- Hbase-分布式列存储数据库
- Hive-数据仓库
- Tez
- OOzie-工作流调度系统
- Hue (Hadoop user Experience)大数据协作框架,web 访问
- Impala (数据查询系统)
- Sentry(事件日志记录和汇集的平台)【哨兵】
- Solr(全文搜索服务器,基于 lucene)
- Lucene
- pig
- Ambari
- Storm(实时处理框架)【暴风雨】
- Kylin【麒麟】
- Kibana
- Kafka(分布式消息队列)
- Azkaban(批量工作流任务调度器)
- Nginx(反向代理服务器)
- spark 和 spark2(大数据处理的计算引擎)
- 大数据相关技术简介
- 参考资源
参考资源
大数据生态圈
大数据特征:
1)大量化(Volume):存储量大,增量大
TB->PB
2)多样化(Variety):
来源多:搜索引擎,社交网络,通话记录,传感器
格式多:(非)结构化数据
,文本、日志、视频、图片、地理位置等
3)快速化(Velocity):
海量数据的处理需求不再局限在离线计算当中
4)价值密度低(Value):
但是这种价值需要在海量数据之上,通过数据分析与机器学习更快速的挖掘出来
大数据带来的革命性变革:
1)成本降低
2)软件容错,硬件故障视为常态
3)简化分布式并行计算
1.1. 大数据常用技术简介
Flume-日志收集工具
Flume 数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。同时,Flume 还具备能够将日志写往各种数据目标的能力。
概念:
- 架构
- agent 用于采集数据
- collector 用户数据汇总
- storage 是存储系统
sqoop-数据同步传输工具
用于 hadoop(hive)与传统数据库的数据传输。 ETL
Zookeeper-分布式协作服务
一个分布式的,开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现。
Zookeeper 解决分布环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。Hadoop 的许多组件依赖于 Zookeeper,它运行在计算集群上面,用户管理 Hadoop 操作。分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
快速理解:
Zookeeper 的核心功能,文件系统和通信机制。
概念:
- 核心功能
- 文件系统
- 每个目录都是一个 znode 节点;Znode 节点可直接存储数据;类型,持久化
- 通信机制
- 客户端监听关心的 Znode 节点;znode 节点有变化时,通知客户端
- 文件系统
- 核心
- 原子广播,保证了各个 Server 之间的同步。实现这种机制的协作叫做 ZAB 协议。(Zookeeper Atomic BrodCast)
ZAB 协议:
核心算法 paxos 算法,一种基于消息传递且具有高度容错性的一致性算法。分布式系统中的节点通信存在两种模型,共享内存,消息传递。paxos 算法解决的问题是一个可能发生上述异常的分布式系统中如何就某个值达成一致,保证不论发生以上任何异常,都不会破坏决策的一致性。
Hbase-分布式列存储数据库
hbase 是运行在 hdfs 之上的一种数据库,以键值对的形式存储数据,能够快速在主机内数十亿行数据中定位所需的数据并访问,而 HDFS 缺乏随即读写操作,不能满足实时需求。
概念:
- 特性:
- 海量数据存储
- 准实时查询,100ms
- 特点:
- 容量大,百亿行,百万列
- 面向列,列式存储,可单独对列进行操作
- 扩展性,底层依赖于 HDFS,动态增加机器即可
- 可靠性,HDFS 本身也有备份
- 高性能,LSM 数据结构,Rowkey 有序排序
- Hbase 表结构:
- 列簇,1 张列簇不超过 5 个,列簇没有限制,列只有插入数据才存在,列在列簇中是有序的。eg:个人信息|教育信息|工作经历
- 不支持条件查询,列动态增加,数据自动切分,高并发读写。
1 | 启动方式: |
Hive-数据仓库
Hive 是建立在 hadoop 上的数据仓库基础架构,类似一种 SQL 解析引擎,它将 SQL 语句转成 MapReduce,然后再 Hadoop 上执行。
1 |
|
habse 和 hive 的区别
habse 是基于 Haddoop 实现的数据库,不支持 SQL
hive 是基于 hadoop 实现的数据仓库,适合海量全量数据,支持类 SQL 操作。
数据仓库的特性
数据仓库用称做数据立方体的多维数据结构建模,它是一个从多个数据源收集的信息存储库,存放在一致的模式下,并且通常驻留在单个站点上。
数据仓库是面向主题的、集成的、其数据是随着时间变化而变化的,其数据是不可修改的。
Facebook 领导的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计。像一些 data scientist 就可以直接查询,不需要学习其他编程接口。
Tez
支持 DAG 作业的计算框架,对 MapReduce 的进一步拆分
Hortonworks 主推的优化 MapReduce 执行引擎,与 MapReduce 相比较,Tez 在性能方面更加出色。
OOzie-工作流调度系统
用来管理 hadoop 任务,工作流调度:工作流程的编排、调整,安排事件的触发执行。OOzie 是一个可扩展的工作体系,集成于 Hadoop 的堆栈,用于协调多个 MapReduce 作业的执行。OOzie 的工作流是放置在控制依赖 DAG(有向无环图 Direct Acyclic Graph)的一组动作(例如,hadoop 的 Map/Reduce 作业,Pig 作业等),其中指定了动作执行的顺序。OOzie 使用 hPDL(一种 XML 流程定义语言)来描述这个图。
一个基于工作流引擎的开源框架。由 Cloudera 公司贡献给 Apache 的,它能够提供对 Hadoop MapReduce 和 Pig Jobs 的任务调度与协调。
Hue (Hadoop user Experience)大数据协作框架,web 访问
访问端口:8889
使用 Hue 我们可以在浏览器端的 Web 控制台上与 Hadoop 集群进行交互来分析处理数据,例如操作 HDFS 上的数据,运行 MapReduce Job,执行 Hive 的 SQL 语句,浏览 Hbase 数据库。
Impala (数据查询系统)
提供 SQL 语义,能查询存储在 Hadoop 的 HDFS 和 HBASE 的 PB 级的大数据。Impala 没有使用 MapReduce 进行并行运算,所以 Hive 适合于长时间的批处理查询分析,而 Impala 适合于实时交互式 SQL 查询。
Sentry(事件日志记录和汇集的平台)【哨兵】
Sentry 是一个开源的实时错误报告工具,支持 Web 前后端、移动应用以及游戏。通常我们所说的 Sentry 是指后端,有 Django 编写。
Solr(全文搜索服务器,基于 lucene)
Sentry 是一个独立的企业其搜索应用服务器,它是一个高性能,采用 JAVA5 开发,它对外提供类似于 Web-service 的 API 接口。用户可以通过 HTTP 请求,向搜索引擎提交一定格式的 XML 文件,生成索引。
Lucene
它是一套用于全文检索和搜索的开发源代码程序库。Lucene 提供了一个简单却强大的应用接口程序,能够做全文索引和搜索,它是最受欢迎的免费 Java 信息检索程序库。
pig
Yahoo 开发的,并行地执行数据流处理的引擎,它包含了一种脚本语言,称为 Pig Latin,用来描述这些数据流。Pig Latin 本身提供了许多传统的数据操作,同时允许用户自己开发一些自定义函数用来读取、处理和写数据。在 LinkedIn 也是大量使用
为大型数据集的处理提供抽象,与 MapReduce 相比,Pig 提供了更丰富的数据结构,一般都是多值和嵌套的数据结构。它提供强大的数据变换,包括在 MapReduce 中被忽视的连接 Join 操作。
Ambari
一种基于 web 的工具,支持 hadoop 集群的供应、管理和监控。
Storm(实时处理框架)【暴风雨】
类似于 Hadoop 的实时处理框架,毫秒级。随着越来越多的场景对 Hadoop 的 MapReduce 高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易)等等,大数据实时处理解决方法的应用日趋广泛,其中 Strom 成为流计算技术中的佼佼者。
基本概念:
Storm 的主从架构由 Nimbus(主结点)、zookeeper(协作框架)、supervisor(从节点)和 worker(各个机器)组成。
1)Nimbus 的作用:接收客户端代码,拆分成多个 task,将 task 信息存入 zookeper;将 task 分配给 supervisor,将映射关系存入 zookeeper;故障检测
2)supervisor 的作用:从 Nimbus 目录读取代码,从 zk 上读取分配的 task;启动工作进程 worker 执行任务;检测运行的工作进度 worker.
- worker 的作用:从 zk 上去读取分配的 task,并计算出 task 需要给哪些 task 分布消息;启动一个或多个 Executor 线程执行任务 Task.
4)zookeeper 的作用:协调 Nimbus 与 supervisor 进行通信;协调 supervisor 与 worker 进行通信;保证 Nimbus 的高可用性。
Kylin【麒麟】
一个开源的分布式分析引擎,为 Hadoop 等大型分布式数据平台之上的超大规模数据集提供通过标准 SQL 查询及多维分析(OLAP)的功能,提供亚秒级的交互分析能力。
Tips:ETL(数据仓库技术)
extract,transform,load(抽取)(转换)(加载)
Kibana
它是一个开源的分析和可视化平台,设计用于和 ElasticSearch 一起工作,你用 Kibana 来搜索,查看并存在 ES 索引中的数据进行交互。
常用端口(ES):5601
参考链接:https://blog.csdn.net/u011262847/article/details/78007119
同时附 es-java-api:
https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/java-search.html
Kafka(分布式消息队列)
端口号:9092
主要用于处理活跃的流式数据,这些数据包括网站的 pv,uv。
概念:
- 基本组成部分
- producer
- Broker
- Consumer
- 基本概念
- producer: 消息和数据的生产者,向 kafka 的一个 topic 发布消息的进程、代码、服务,负责发布消息到 Broker.
- Broker: Kafka 集群包含一个或多个服务器,这种服务被称为 Broker.
- Consumer: 消息和数据的消费者,订阅消息,向 Broker 读取消息的客户端。
- Topic: kafka 消息的类别,每条发布到 kafka 集群的消息都有一个类别,这个类别称为 Topic.
- Partition: kafka 下数据存储的基本单元,每个 Topic 包含一个或多个 Partition.
- Consumer Group: 对于同一个 Topic,会广播给不同的 Group。每个 Consumer 属于一个特定的 Consumer Group.
- Replication Leader: 负责 partition 上 Producer 与 Consumer 的交互。
- ReplicaManager: 负责管理当前 Broker 所有分区和副本的信息。
- 特点
- 多分区
- 多副本
- 多订阅者
- 基于 zookeeper 调度
- 应用场景:
- 消息队列
- 行为跟踪
- 元数据监控
- 日志收集
- 流处理,时间源
- 持久性日志
1 | 手动导入数据到 Kafka 命令 |
Azkaban(批量工作流任务调度器)
主要用于在一个工作流内以一个特定的顺序运行一组工作和流程,它的配置是通过简单的 key:value 键值对的方式,通过配置中的 dependencies 来设置依赖关系,这个依赖关系是无环的,否则会被视为无效的工作流。相比于 OOzie 的配置复杂度高,Azkaban 有如下有点:
1)通过 job 配置文件快速建立任务和任务之间的依赖关系。
2)提供功能清晰,简单易用的 web UI 界面。
3)提供模块化和可插拔的插件机制,原生支持 command,java,pig,hadoop。
- 基于 java 开发,代码结构清晰,易于二次开发。
跟上面很像,Linkedin 开源的面向 Hadoop 的开源工作流系统,提供了类似于 cron 的管理任务。
Nginx(反向代理服务器)
它是一个高性能的 HTTP 和反向代理服务器,也是一个 IMAP/POP3/SMTP 代理服务器。Nginx 是一款轻量级的 Web 服务器/反向代理服务器以及电子邮件代理服务器,并在一个 BSD-like 协议下发型,其特点是占有内存小,并发能力强。事实上 nginx 的并发能力确实在同类型的网络服务器中表现较好,中国大陆使用 nginx 网站的有:百度,京东,腾讯,淘宝,网易。
应用:
Nginx 实现负载均衡,链接:https://www.cnblogs.com/JimBo-Wang/p/6556360.html
spark 和 spark2(大数据处理的计算引擎)
Spark 是 UC Berkeley AMP lab 开发的一个集群计算的框架,类似于 Hadoop,但有很多的区别。最大的优化是让计算任务的中间结果可以存储在内存中,不需要每次都写入 HDFS,更适用于需要迭代的 MapReduce 算法场景中,可以获得更好的性能提升。例如一次排序测试中,对 100TB 数据进行排序,Spark 比 Hadoop 快三倍,并且只需要十分之一的机器。Spark 集群目前最大的可以达到 8000 节点,处理的数据达到 PB 级别,在互联网企业中应用非常广泛.
链接:https://www.cnblogs.com/smuxiaolei/p/7663744.html
相关概念:
1)在 spark 中,所有计算都是通过 RDDS 的创建、转化和操作完成的。RDDS(Resilent Distributed datasets,弹性分布式数据集)是并行分布在整个数据集中,是 spark 分发数据和计算的基础抽象类。
2)Spark 运行架构包括集群资源管理器(Cluster Manager),运行作业任务的工作节点(worker Node),每个应用的任务控制节点(Driver)和每个工作节点上负责任务的执行进程(Executor).
Spark 程序的执行过程:
1)创建 SparkContext 对象
2)从外部数据源读取数据,创建 fileRDD 对象
3)构建依赖关系,fileRDD->filterRDD,形成 DAG
4)Cache()缓存,对 filterRDD 进行持久化
5)Count()执行。
spark 基础:http://dblab.xmu.edu.cn/blog/spark/
与 Hadoop MapReduce 比较:
1)spark 采用多线程来执行任务,而 MapReduce 采用多进程,优点是减少了任务开销。
2)Excutor 中有一个 BlockManager 存储模块,会将内存和磁盘共同作为存储设备,当需要多轮时,可将中间结果存储到这个模块中,下次需要时,可以直接读取,不需要读写到 HDFS 等文件系统中,减少 IO 开销。
3)实例:100T 的数据量,spark 206 个节点,只需 23 分钟;MapReduce 2000 个节点,需要 72 分钟。
链接:http://dblab.xmu.edu.cn/blog/985-2/
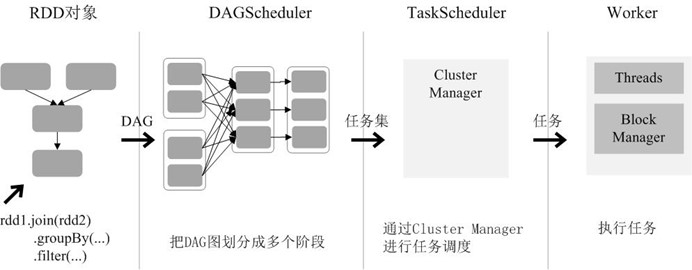
RDD 在 Spark 架构中的运行过程(如图所示):
(1)创建 RDD 对象;
(2)SparkContext 负责计算 RDD 之间的依赖关系,构建 DAG;
(3)DAGScheduler 负责把 DAG 图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的 Executor 去执行。
大数据相关技术简介
- Platfora
- 大数据发现和分析平台。
- Qlikview
- 引导分析平台。
- Sisense
- 商业智能软件,专门处理复杂数据的商业智能解决方案。
- Sqream
- 快速、可扩展的大数据分析 SQL 数据库。
- Splunk
- 运维智能平台。
- Sumologic
- 安全的、专门定制的、基于云的机器数据分析服务。
- Actian
- 大数据分析平台。
- 亚马逊 Redshift
- PB 级云端数据仓库服务。
- CitusData
- 可扩展 PostgreSQL。
- Exasol
- 用于分析数据的大规模并行处理(MPP)内存数据库。
- 惠普 Vertica
- SQL on Hadoop 大数据分析平台。
- Mammothdb
- 与 SQL 兼容的 MPP 分析数据库。
- 微软 SQL Server
- 关系数据库管理系统。
- 甲骨文 Exadata
- 计算和存储综合系统,针对甲骨文数据库软件进行了优化。
- SAP HANA
- 内存计算平台。
- Snowflake
- 云数据仓库。
- Teradata
- 企业级大数据分析和服务。
数据搜索引擎
- Apache Drill
- 无数据库模式的 SQL 查询引擎,面向 Hadoop、NoSQL 和云存储。
- Cloudera Impala
- 开源大规模并行处理 SQL 查询引擎。
- 谷歌 BigQuery
- 全面托管的 NoOps 数据分析服务。
- Presto
- 面向大数据的分布式 SQL 查询引擎。
- Spark
- 用于处理大数据的快速通用引擎。
平台/基础设施
- 亚马逊网络服务(AWS)
- 提供云计算服务
- 思科云
- 提供基础设施即服务
- Heroku
- 为云端应用程序提供平台即服务
- Infochimps
- 提供云服务的大数据解决方案
- 微软 Azure
- 企业级云计算平台。
- Rackspace
- 托管专业服务和云计算服务
- Softlayer(IBM)
- 提供云基础设施即服务
数据基础设施
- Cask
- 面向 Hadoop 解决方案的开源应用程序平台。
- Cloudera
- 提供基于 Hadoop 的软件、支持和服务。
- Hortonworks
- 管理 HDP――开源企业 Apache Hadoop 数据平台。
- MAPR
- 面向大数据部署环境的 Apache Hadoop 技术。
垂直领域应用/数据挖掘
- Alpine Data Labs
- 高级分析平台,可处理 Apache Hadoop 和大数据。
- R
- 免费软件环境,可处理统计计算和图形。
- Rapidminer
- 开源预测分析平台
- SAS
- 软件套件,可以挖掘、改动、管理和检索来自众多数据源的数据。
提取、转换和加载(ETL)
- IBM Datastage
- 使用一种高性能并行框架,整合多个系统上的数据。
- Informatica
- 企业数据整合和管理软件。
- Kettle-Pentaho Data Integration
- 提供了强大的提取、转换和加载(ETL)功能。
- 微软 SSIS
- 用于构建企业级数据整合和数据转换解决方案的平台。
- 甲骨文 Data Integrator
- 全面的数据整合平台。
- SAP NetWeaver
- 为整合来自各个数据源的数据提供了灵活方式。
- Talend
- 提供了开源整合软件产品
- Cassandra
- 键值数据库和列式数据库的混合解决方案。
- CouchBase
- 开源分布式 NoSQL 文档型数据库。
- Databricks
- 使用 Spark 的基于云的大数据处理解决方案。
- Datastax
- 为企业版的 Cassandra 数据库提供商业支持。
- IBM DB2
- 可扩展的企业数据库服务器软件。
- MemSQL
- 分布式内存数据库。
- MongoDB
- 跨平台的文档型数据库。
- MySQL
- 流行的开源数据库。
- 甲骨文-Oracle等软件
- 企业数据库软件套件。
- PostgresSQL
- 对象关系数据库管理系统。
- Riak
- 分布式 NoSQL 数据库。
- Splice Machine
- Hadoop 关系数据库管理系统。
- VoltDB
- 内存 NewSQL 数据库。
- Actuate
- 嵌入式分析和报表解决方案。
- BiBoard
- 交互式商业智能仪表板和可视化工具。
- Chart.IO
- 这是面向数据库的企业级分析工具。
- IBM Cognos
- 商业智能和绩效管理软件。
- D3.JS
- 使用 HTML、SVG 和 CSS 可视化显示数据的 JavaScript 库。
- Highcharts
- 面向互联网的交互式 JavaScirpt 图表。
- Logi Analytics
- 自助服务式、基于 Web 的商业智能和分析应用软件。
- 微软 Power BI
- 交互式数据探查、可视化和演示工具。
- Microstrategy
- 企业商业智能和分析软件。
- 甲骨文 Hyperion
- 企业绩效管理和商业智能系统。
- Pentaho
- 大数据整合和分析解决方案。
- SAP Business Objects
- 商业智能解决方案。
- Tableau
- 专注于商业智能的交互式数据可视化产品系列。
- Tibco Jaspersoft
- 商业智能套件